Databricks on Azure - An architecture perspective (part 1)

Francisco Linaje
AWS Solutions Architect
Gabriel Gallardo Ruiz
Senior Data Architect

Databricks aims to provide an intuitive environment for the non-specialist users to develop the different functions in data engineering and data science, also providing a data governance and management layer.
Our goal with this article is not focus so much to describe and analyze how to use these tools, but to see how they are integrated from an architectural point of view within the Azure provider.
Databricks as a Lakehouse solution
The Databricks platform follows the Lakehouse paradigm, in which the benefits of the Data Warehouse are combined with those of the Data Lake, allowing to have a good performance both in its analytical queries thanks to indexing, and transactionality through Delta Lake, without losing the flexibility of an open and scalable data architecture, along with better data governance and access to the resources and services of the lake, allowing in a general way to have a less complex and more integrated architecture.
This article will be divided into two deliverys.
- The first one, will explain how Databricks organizes and deploys its product on Azure, as well as the different configurations in terms of communication/security between Databricks and other Azure services.
- The second, will be focused on the data security layer and scalability of the infrastructure as well as monitoring, deployment and failover.
First delivery:
- Architecture Overview
- Workload types and plans
- Networking
- Identity and Access Management
Second delivery (coming soon):
- Disaster Recovery
- Encryption
- Scalability
- Logging and monitoring
- Deployment
Glossary
- Azure Data Lake: Allows to store multiple data formats in the same place for its exploitation and analysis, currently Azure has the Gen2 version.
- All Purpose Compute: Designed for collaborative environments in which the cluster is used simultaneously by Data Engineers and Data Scientist.
- Azure Key Vault: Azure managed service that enables secure storage of secrets.
- Azure Virtual Network (VNET): Logically isolated virtual network in Azure.
- Azure role-based access control (RBAC): Authorization system integrated into Azure Resource Manager that allows you to assign granular permissions on resources to Azure users.
- Continuous integration and continuous delivery CI/CD: A set of automated tools and guidelines for continuous integration and production start-up.
- Data Lake: Paradigm of distributed storage of data from a multitude of sources and formats, structured, semi-structured and unstructured.
- Identity Provider (IdP): Entity that maintains the identity information of individuals within an organization.
- Jobs Compute: Focused on processes orchestrated through pipelines managed by data engineers that may involve auto-scaling in certain tasks.
- Jobs Light Compute: Designed for processes whose achievement is not critical and does not involve a very high computational load.
- Network Security Group or NSG: Specifies the rules that regulate inbound and outbound network traffic and clusters in Azure.
- Notebook: Web interface to execute code in a cluster, abstracting from the access to it.
- PrivateLink: Allows private access (private IP) to Azure PaaS through your VNET, in the same way that service endpoints traffic is routed through the Azure backbone.
- Security Assertion Markup Language (SAML): Open standard used for authentication. Based on XML, web applications use SAML to transfer authentication data between two entities, the Identity Provider and the service in question.
- Secure Cluster Connectivity (SCC): SSH reverse tunnel communication between Control Plane and cluster. It allows not having open ports or public IPs in the instances.
- Service endpoints: Network component that allows connecting a VNET with the different services within Azure through Azure’s own network.
- Service Principal: Entity created for the administration and management of tasks that are not associated to a particular member of the organization but to a service.
- Secret scope: Collection of secrets identified by a name.
- Single Sign On (SSO): Allows users to authenticate through an Identity Provider (IdP) provided by the organization, requiring SAML 2.0 compatibility.
- Workspace: Shared environment to access all Databricks assets. It organizes the different objects (notebooks, libraries, etc…) in folders and manages access to computational resources such as clusters and jobs.
Architecture
Databricks as a product
Databricks remains integrated within Azure as its own service unlike other providers, allowing the deployment in a more direct and simple way either from the console itself or through templates.
Among the services offered by Databricks, the following stand out:
- Databricks SQL: offers a platform to perform ad-hoc SQL queries against the Data Lake, as well as multiple visualizations of the data with dashboards.
- Databricks Data Science & Engineering: provides a workspace that allows collaboration between different roles (data engineers, data scientists, etc.) for the development of different pipelines for the ingestion and exploitation of the Data Lake.
- Databricks Machine Learning: provides an environment for the development and exploitation of end-to-end machine learning models.
Databricks also offers Spark as a distributed programming framework, as well as integration with Delta Lake and its support for ACID transactions for structured and unstructured data, unification of batch sources and streaming.
Databricks also offers a solution in terms of orchestration and deployment of jobs in a productive way, allowing parallelism between them, up to 1000 concurrently. It can be used only within the Data Science & Engineering workspace.

Among the added benefits offered by Databricks is the use of Databricks File System (DBFS), a distributed file system for cluster access.
- It allows mounting storage points to access objects without the need for credentials.
- It avoids the need to use urls to access objects, facilitating access via directories and semantics.
- It provides a layer of persistence by storing data in the file system, preventing it from being lost when the cluster is terminated.
Databricks Repos: offers integration and synchronization with GIT repositories, including an API for the use of CI/CD pipelines. Current Git providers included are:
- GitHub
- Bitbucket
- GitLab
- Azure DevOps
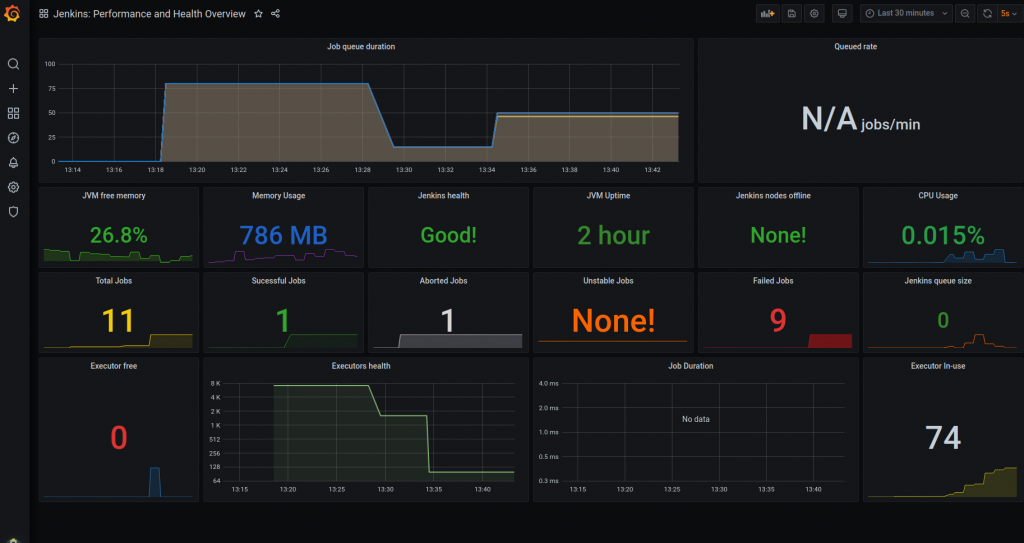
Architecture Overview
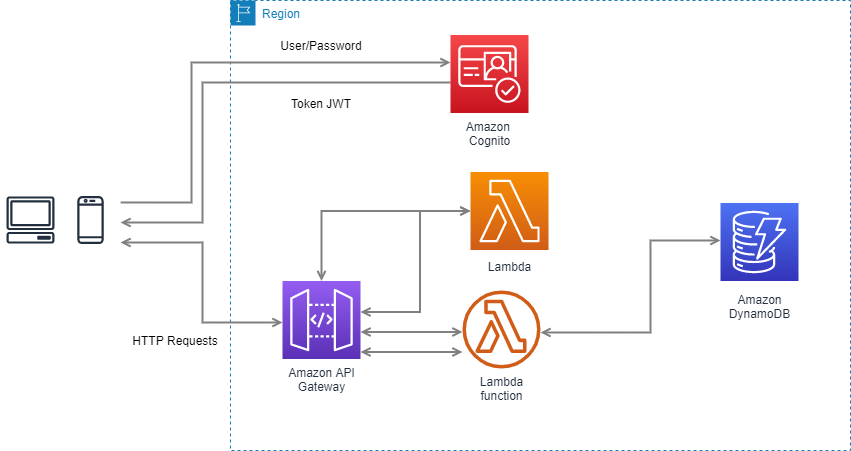
In this section we will discuss how Databricks is deployed within the customer’s account in their cloud provider, in this case Azure.
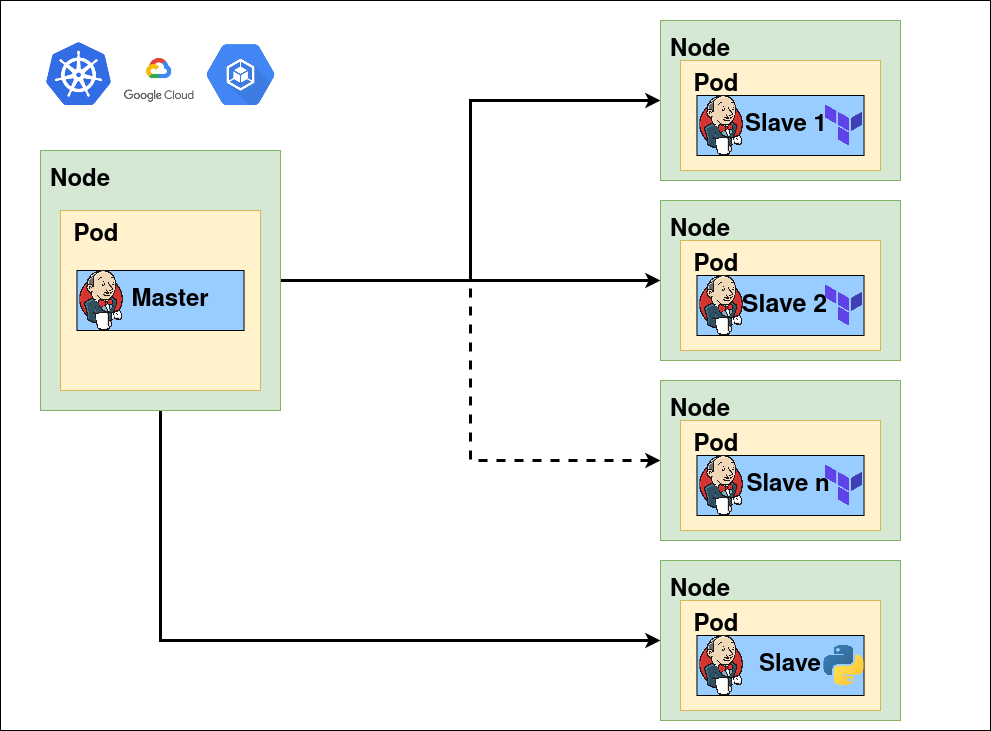
Databricks is primarily composed of two layers; a Control Plane (internal) and a Data Plane (external/client).

In the previous image we can see how the Control Plane remains in the databricks subscription, under its control, design and internal administration being shared by all users.
The main services contained are:
- Notebooks: All notebooks, results and configurations remain encrypted.
- Job Scheduler
- Rest API
- Metastore: Hive metastore managed by databricks
- Cluster manager: Requests virtual machines for clusters to be launched on the Data Plane.
The Data Plane is inside the customer’s subscription and will therefore be managed by him. In this layer we find the jobs and clusters used for the execution of the ETLs, as well as the data used in them.
It is important to note that Databricks provides two network interfaces in each deployed node, one of them will route the traffic to the Control Plane and the other one will route the internal traffic between nodes (driver – executors).
Databricks offers two main methods to deploy the Data Plane, which we will discuss in depth later:
- On the one hand we have Databricks managed VNET, this being the deployment given by default where Databricks takes care of deploying the necessary resources within the client account.
- On the other hand we have a second type of deployment Databricks VNET injection where the client is the one that provides the minimum resources necessary for the correct operation and communication against the control-plane.
In both cases, the network topology in the Data Plane will be composed of two subnets.
- Container subnet or “private” subnet.
- Host subnet or “public” subnet.

Secure Cluster Connectivity [2]
In more restrictive security contexts, it will be possible to assign a NAT gateway or other egress traffic devices such as a load balancer, firewall, etc, as a gateway to eliminate the need to assign public IP addresses to hosts.

Workload plans and types
In addition to the cost of the infrastructure used for processing and storage in Azure, Databricks performs a load expressed in DBU (processing units) depending on the type of instance lifted and its size, as well as the type of workload used. We distinguish 2 main types:
- Jobs Cluster: for execution of scheduled non-iterative pipelines, distinguished according to the size of the provisioned cluster into light or normal.Jobs are usually used by creating ephemeral clusters and being deleted after the execution of the jobs.
- All purpose: Clusters used to work iteratively (MANDATORY for this use) allowing to run and develop different notebooks concurrently.
In addition, depending on the type of Standard or Premium account contracted, additional charges will be made on the cost of the DBU.
| AZURE PLAN | ||
|---|---|---|
| | Standard | Premium |
| | One platform for your data analytics and ML workloads | Data analytics and ML at scale across your business |
| Job Light Compute | $0,07/DBU | $0,22/DBU |
| Job Compute | $0,15/DBU | $0,30/DBU |
| SQL Compute | N/A | $0,22/DBU |
| All-Purpose Compute | $0,40/DBU | $0,55/DBU |
Imputed cost per DBU for computational and architectural factors
| WORKLOAD TYPE (STANDARD TIER) | |||
|---|---|---|---|
| FEATURE | Jobs Light Comput | Jobs compute | All-purpose compute |
| Managed Apache Spark | | | |
| Job scheduling with libraries | | | |
| Job scheduling with notebooks | | | |
| Autopilot clusters | | | |
| Databricks Runtime for ML | | | |
| Managed MLflow | | | |
| Delta Lake with Delta Engine | | | |
| Interactive clusters | | | |
| Notebooks and collaboration | | | |
| Ecosystem integrations | | | |
Characteristics by type of workload Standard plan
| WORKLOAD TYPE (STANDARD TIER) | |||
|---|---|---|---|
| FEATURE | Jobs Light Comput | Jobs compute | All-purpose compute |
| Role Based Access Control for clusters, jobs, notebooks and tables | | | |
| JDBC/ODBC Endpoints Authentication | | | |
| Audit Logs | | | |
| All Standard Plan Features | | | |
| Azure AD credential passthrough | | | |
| Conditional Authentication | | | |
| Cluster Policies | | | |
| IP Access List | | | |
| Token Management API | | | |
Features by workload type Premium plan
It is important to note that it is also possible to obtain discounts of up to 37% in the prices per DBU, by making purchases of these (DBCU or Databricks Commit Units) for 1 or 3 years.
Networking
In this section we will explain the two different types of deployment discussed above and their peculiarities in terms of connection and access to the Control Plane, as well as incoming/outgoing traffic control.
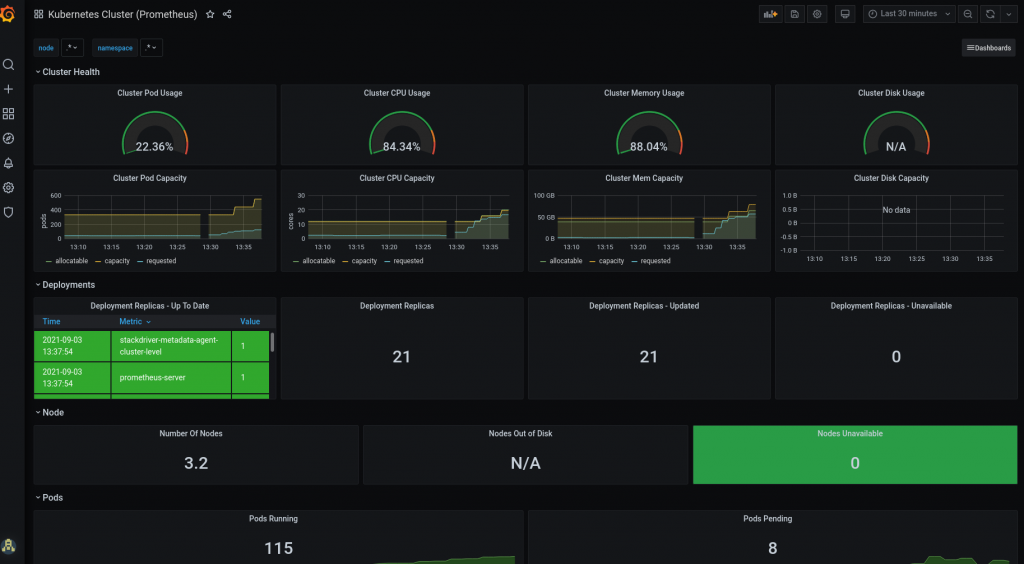
Network managed by Databricks
In this alternative, Azure allows Databricks to deploy the Data Plane over our subscription, making available the resources that will allow the connection against the Control Plane and the deployment of jobs, clusters and other resources.
- The communication between the Data Plane and the Control Plane, regardless of having Secure Cluster Connectivity (SCC) enabled, will be done through Azure’s internal backbone, without routing traffic over the public network.
- Secure Cluster Connectivity (SCC) can be enabled to work without public IPs.
- The inbound/outbound traffic of the clusters will be controlled by different rules by the network security group NSG that cannot be modified by the user.
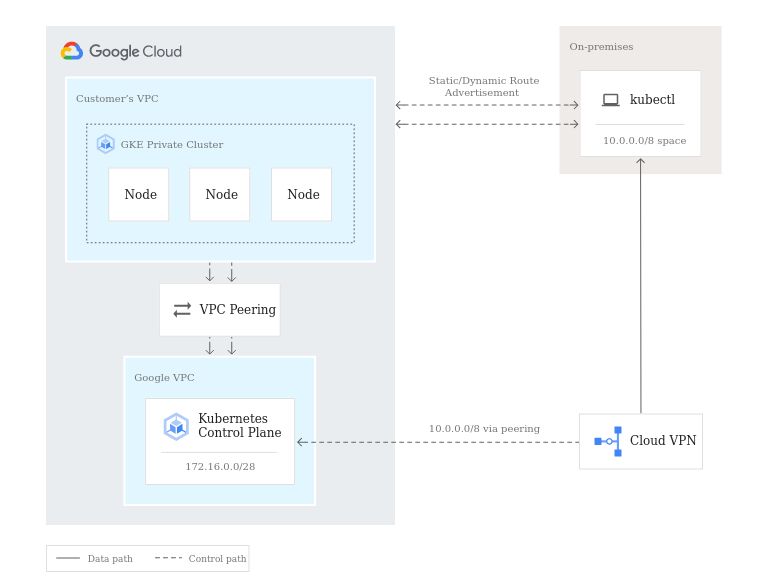
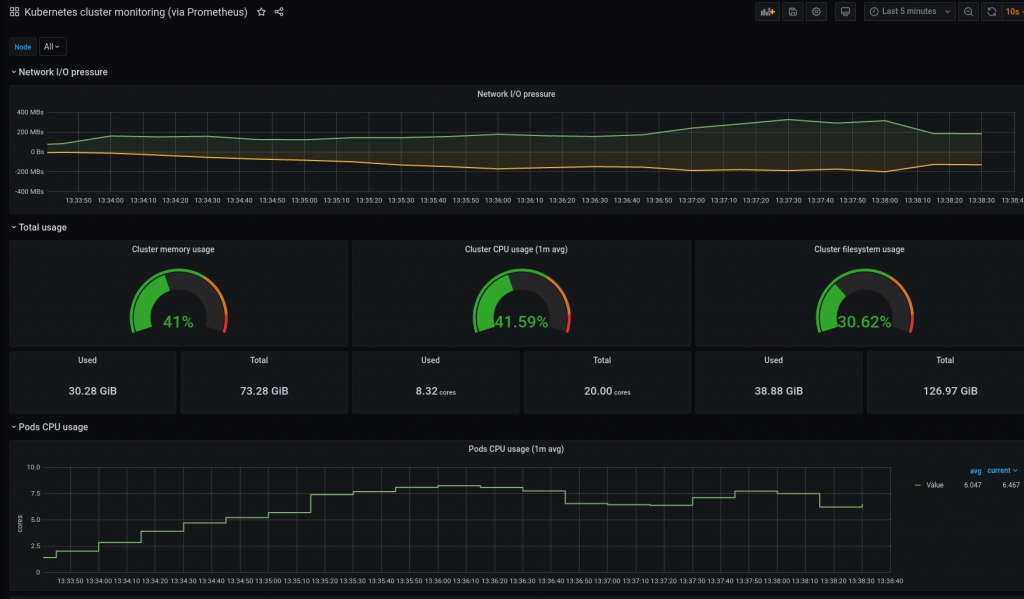
Customer managed network (VNET injection) [1]
Databricks offers the possibility of being able to deploy the Data Plane over our own VNET managed by us. This solution offers greater versatility and control over the different components of our architecture.
- The communication between the Data plane and Control Plane will be done over the internal Azure backbone in the same way as in the network managed by Databricks seen above, also in the same way we can activate SCC.
- In this case when owning our own VNET, we will have control over the rules defined in our NSGs.

- You must be the owner of the VNET to allow Databricks to be delegated its configuration or resource deployment [3].
- We will be able to enable any architecture component we consider within our VNET as it will be managed by us:
- Connect Azure Databricks to other Azure services in a more secure way employing service endpoints or private endpoints.
- Connect to your on-premise resources using user-defined routes.
- Allows you to deploy a virtual network appliance to inspect traffic.
- Custom DNS
- Custom egress NSG rules
- Increase the CIDR range of the network mask for the VNET between /16 – /24 and /26 for the subnets.

Among the peculiarities of both deployments, it is important to point out:
- It is not possible to replace an existing VNet in a workspace with another one, if it was necessary a new workspace, a new VNET must be created.
- It is also not possible to add SCC to the workspace once it has already been created, if it was necessary, the workspace must also be recreated.
Connections against the Control Plane

As we have previously discussed, all communication with the Control Plane is done inside the Azure backbone by default [2]. It should also be noted:
- At the network level, any connection made against the Control Plane when creating a cluster in the Data Plane is made via HTTPS (443) and over a different IP address than the one used for other Web application services or APIs.
- When the Control Plane launches new jobs or performs other cluster administration tasks, these requests are sent to the cluster through this reverse tunnel.
- To make connections between the Control and Data Plane, a public IP address will be enabled on the public subnet even if the traffic is subsequently routed within the backbone, and no ports will be left open or public IP addresses will be assigned on the clusters.
- If in our use case more restrictive security conditions must be used, Databricks offers the possibility to activate the secure cluster connectivity option or , allowing to remove all public IP addresses to make the connection between the control and Data Plane, for this purpose will be used:
- By default in the network managed by Databrics (managed VNET) a NAT is enabled to be able to perform this communication.
- If the customer deploys the infrastructure on its own network (VNET Injection deployment) it must provide a network device for outgoing traffic, which could be a NAT Gateway, Load Balancer, Azure Firewall or a third party device.
Identity and Access Management
Databricks offers different tools to manage access to our Azure resources and services in a simple and integrated way in the platform itself.
We can find tools such as IP filtering, SSO, usage permissions on Databricks services, access to secrets, etc.
IP access lists
Databricks allows administrators to define IP access lists to restrict access to the user interface and API to a specific set of IP addresses and subnets, allowing access only from the organization’s networks, and administrators can only manage IP access lists with the REST API.
Single sign on (SSO)
Through Azure Active Directory we will be able to configure SSO for all our Databricks users avoiding duplication in identity management.
System for Cross-domain Identity Management (SCIM)
Allows through an IdP (currently Azure Active Directory) to create users in Azure Databricks and grant them a level of permissions and stay synchronized, you must have a PREMIUM plan. If permissions are revoked the resources linked to this user are not deleted.
Access to resources
The main access to the different Databricks services will be given by the entitlements where it will be indicated if the group/user will have access to each one of them (cluster creation, Databricks SQL, Workspaces).
On the other hand, within Databricks ACLs can be used to configure access to different resources such as clusters, tables, pools, jobs and workspace objects (notebooks, directories, models, etc). Granting this granularity on access to resources is only available through the PREMIUM plan, by default all users will have access to resources.
These permissions are managed from the administrator user or other users with delegated permissions.
There are 5 levels of permissions with their multiple implications depending on the resource to which they apply; No permissions, can read, can run, can edit, can manage.
The permissions associated with the resource to be used are indicated below. If two policies may overlap, the more restrictive option will take precedence over the other.



Azure Datalake Storage
Through Azure Active Directory (Azure AD) you can authenticate directly from Databricks with Azure Datalake Storage Gen1 and 2, allowing the Databricks cluster to access these resources directly without the need of a service principal. Requires PREMIUM plan and enable credential passthrough in advanced options at the time of cluster creation in Databricks. Available in Standard and High Concurrency clusters.

Credential passthrough is an authentication method that uses the identity (Azure AD) used for authentication in Databricks to connect to Datalake. Access to data will be controlled through the RBAC roles (user level permissions) and ACLs (directory and file level permissions) configured.
Access control lists (ACLs) control access to the resource by checking if the entity you want to access has the appropriate permissions.
Secrets [5].
Access
By default, all users regardless of the contracted plan can create secrets and access them (MANAGE permission). Only through the PREMIUM plan it is possible to configure granular permissions to control access. The management of these can be done through Secrets API 2.0 or Databricks CLI (0.7.1 onwards).
Secrets are managed at the scope level (collection of secrets identified by a name), specifically an ACL controls the relationship between the principal (user or group), the scope and the permission level. For example: when a user accesses the secret from a notebook via Secrets utility the permission level is applied based on who executes the command.
By default, when a scope is created a MANAGE permission level is applied to it, however the user who creates the scope can add granular permissions.
We distinguish 3 permission levels in Databricks-backed scopes:
- MANAGE: can modify ACLs and also has read and write permissions on the scope.
- WRITE: has read and write permissions on the scope.
- READ: only has read permissions on the scope and the secrets to which it has access.
The administrator users of the workspace have access to all the secrets of all the scopes.
Storage
The secrets can be referenced from the scopes that in turn will reference their respective vaults where the secrets are stored.
There are two types of storage media for secrets:
- Databricks-backed
- Azure Key Vault
We can use Databricks-backed as a storage medium for the secrets without the need for a PREMIUM plan, however either to use Azure Key Vault or on the other hand the use of granular permissions in both cases, it will be necessary to hire the PREMIUM plan.
It is important to note that if the Key Vault exists in a different tenant than the one hosting the Databricks workspace, the user creating the scope must have permissions to create service principals on the tenant’s key vault, otherwise the following error will be thrown.
Unable to grant read/list permission to Databricks service principal to KeyVault Because Azure Key Vault is external to Databricks, only read operations will be possible by default and cannot be managed from the Secrets API 2.0, Azure SetSecrets REST API or from the Azure UI portal must be used instead.
It is important to note, that all users will have access to the secrets of the same KEY VAULT even if they are in different scopes, it is considered good practice to replicate the secrets in different Key Vaults according to subgroups even if they may be redundant.
Now with RBAC [4] (role-based access control) it is possible to control the access to the secrets of the Vault that have this service activated through different roles, these roles must be assigned to the user.
The scopes can be consumed from the dbutils library, if the value is loaded correctly it appears as REDACTED.
dbutils.secrets.get(scope = "scope_databricks_scope_name", key = "secret_name") On-premise connections
Finally, it is necessary to comment that it is also possible to establish an on-premise connection for our Data Plane in Azure, for this it is essential that it is hosted in our own network (VNET injection).

Azure defines as the main method to establish this on-premise connection using Transit Virtual Network, following these steps:
- Create a Network Gateway (VPN or ExpressRoute) between the transit network and on-premise, for this we must create both the Customer Gateway on the on-premise side and the Virtual Gateway on the Azure side.
- Establish the peering between the Data Plane and the transit network. Once the peering is established Azure Transit configures all the routes, however the return routes to the Control Plane for the Databricks clusters are not included, for this the user-defined routes should be configured and associated to the subnets of the Data Plane.
Other alternative solutions could also be employed through the use of Custom DNS or the use of a virtual appliance or firewalls.
Referencias
[1] Customer-managed VNET Databricks guide. [link] (January 26, 2022)
[2] Secure Cluster Connectivity. [link] (January 26, 2022)
[3] Subnetwork Delegation. [link] (January 3, 2022)
[4] Role-based access control [link] (October 27, 2021)
[5] Databricks secret scopes [link] (January 26, 2022)
Do you want to know more about what we offer and to see other success stories?
Francisco Linaje
AWS Solutions Architect
Gabriel Gallardo Ruiz
Senior Data Architect
SOLUTIONS, WE ARE EXPERTS
You may be interested in