Snowflake: Zero-Copy clone, o cómo librarte del duplicado de datos al clonar.

Roberto García Parra
Technical Delivery Manager
Gabriel Gallardo Ruiz
Enterprise Architect

Introducción
Cómo continuación a la serie de artículos que estamos haciendo sobre las funcionalidades avanzadas que se derivan de la forma en la que se almacenan los datos en Snowflake, presentamos este nuevo artículo sobre el Zero-copy clone, que permite mediante diferentes operaciones a nivel metadato poder tener diferentes copias o versiones de la información, sin tener que duplicar datos en la mayoría de las ocasiones.
¿Qué es Zero-Copy Clone?
Uno de los casos de uso más frecuente que implica gran consumo de tiempo, recursos y almacenamiento, especialmente si hablamos de grandes dataset, es el copiado de datos. Para la realización de copias de objetos, snowflake ofrece zero-copy clone. Esta operación se realiza sobre la metadata, lo que permite realizar clonado de objetos rápidamente sin tener que duplicar los datos.
¿Cómo funciona?
Snowflake realmente lo que realiza es una copia de la metadata asociada al objeto que se va a clonar. Como podemos ver en el ejemplo de clonación de la tabla ‘Events’ en la siguiente imagen, simplemente duplica la metadata sin realizar ningún cambio en la parte de almacenamiento.
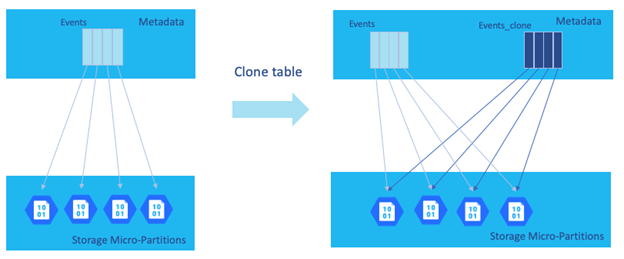
Una vez realizado el clon, los objetos clonados tienen su propio ciclo de vía, lo que permite que se puedan realizar cambios sobre los datos sin afectar al objeto original, de igual modo los cambios realizados sobre el objeto original tampoco serán reflejados sobre el objeto clonado.
Zero-copy clone permite la realización de clones prácticamente de cualquier objeto de Snowflake siendo especialmente útil en bases de datos, esquemas y tablas.
¿Qué coste tiene?
Al tratarse de una operación exclusiva de metadata, no se repercuten costes ni de procesamiento ni de almacenamiento, ni siquiera es necesario realizar la operación con un virtual data warehouse activo.
¿Cómo se puede clonar una tabla?
Privilegios: Para poder clonar una tabla, el ROLE que va a realizar la clonación tiene que tener privilegios de SELECT sobre la tabla que se va a clonar, además como es lógico, privilegios de CREATE TABLE sobre el esquema destino en el que se va a crear el clon de la tabla.
Sentencia: La sentencia utilizada para la clonación de tablas es similar a la de creación pero añadiendo la cláusula CLONE. A continuación, vamos a clonar la tabla “events»:
USE ROLE INGESTA_HUB_ROLE;
USE SCHEMA WEATHER.HISTORICAL;
CREATE TABLE EVENTS_CLONE CLONE EVENTS;
Podemos comprobar que la clonación de la tabla se realiza de inmediato, ya que como se comentó anteriormente únicamente se opera sobre la metadata.
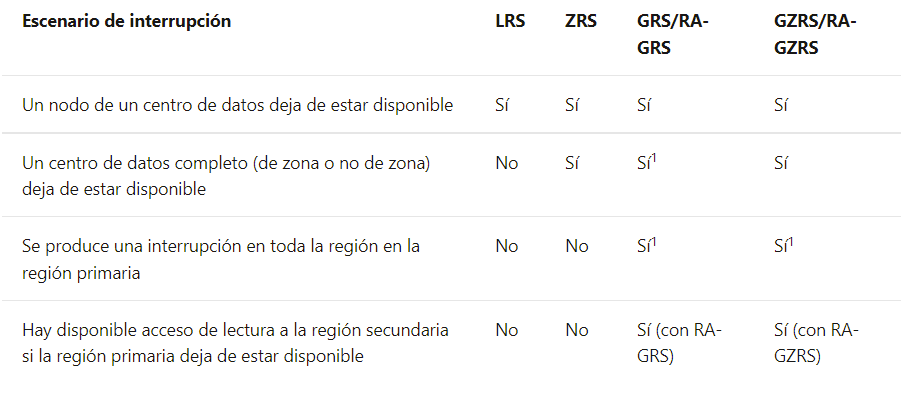
Además, podemos observar en la siguiente tabla que todas las propiedades de la tabla origen se han clonado en la nueva tabla. Únicamente en el caso en que la tabla origen tenga asignado una cluster key, la nueva tabla se creará con automatic_clustering suspendido.
| EVENTS | EVENTS | |
|---|---|---|
| cluster_by | LINEAR (COUNTRY,CITY) | LINEAR (COUNTRY,CITY) |
| rows | 7,479,165 | 7,479,165 |
| bytes | 105,110,528 | 105,110,528 |
| owner | INGESTA_HUB_ROLE | INGESTA_HUB_ROLE |
| retention_time | 30 | 30 |
| automatic_clustering | ON | OFF |
| change_tracking | OFF | OFF |
| search_optimization | OFF | OFF |
| is_external | N | N |
Con respecto a los privilegios, por defecto no serán clonados. Esto lo podemos comprobar con las sentencias siguientes:
SHOW GRANTS ON TABLE WEATHER.HISTORICAL.EVENTS;

SHOW GRANTS ON TABLE WEATHER.HISTORICAL.EVENTS_CLONE;
Para que se clonen los privilegios asignados a la tabla origen, hay que añadir COPY GRANTS en la sentencia de clonado:
CREATE TABLE EVENTS_CLONE_1 CLONE EVENTS COPY GRANTS;
Ahora podemos comprobar que los privilegios han sido clonados:
SHOW GRANTS ON TABLE WEATHER.HISTORICAL.EVENTS_CLONE;

Clonación usando time travel
Snowflake permite realizar la clonación de una tabla para un momento histórico determinado, para ello tendremos que utilizar la cláusula AT o BEFORE en la sentencia de clonado.
Para la ejecución de la prueba, vamos a hacer cambios en la tabla de EVENTS y después realizaremos el clonado con un time travel anterior al cambio.
DELETE FROM EVENTS WHERE AIRPORTCODE=’KS47′;
Clonamos la tabla con un time travel anterior a la realización del borrado
CREATE TABLE EVENTS_CLONE_TIME_TRAVEL CLONE EVENTS at (offset => -60*5);
Si consultamos la información referente a ambas tablas, podemos comprobar que el clonado se ha realizado en el momento anterior en el que la tabla EVENTS tenía 9.062 filas más.


Consideraciones del clonado de tablas
- Actualmente las tablas externas no pueden ser clonadas.
- La tabla clonada tiene su propio ciclo de vida con lo que no tiene acceso a los datos históricos de la tabla origen utilizando time travel.
- Una tabla clonada no incluye el historial de carga(LOAD_HISTORY) de la tabla de origen.
- Si se clona una tabla con una secuencia asignada como valor por defecto a una columna, ésta seguirá referenciando a la secuencia original. En el caso de clonación de base de datos o esquemas que contengan tanto la secuencia como la tabla, la columna referenciará a la secuencia clonada (esto lo veremos con un ejemplo en la parte de clonado de Esquemas y Bases de dato)
- Si clonamos una tabla que contiene a una foreign key, esta seguirá haciendo referencia a la tabla con al primary key. Como pasaba en el caso de las secuencias, si la clonación se realiza sobre un esquema o una base de datos y contiene ambas tablas, las referencias se realizan sobre las clonadas. En el caso de que la referencia de la foreign key sea sobre otra base de datos, seguirá realizándose sobre la tabla que contiene la primary key.
¿Cómo realizar la clonación de Esquemas y Base de datos?
Privilegios: Para poder clonar una base de datos o un esquema en Snowflake el role que va a realizar la operación tiene que tener permisos USAGE sobre los objetos que se van a clonar y los privilegios adecuados para la creación de los objetos en el destino.
La realización de clonado de un esquema o de una base de datos se realiza de manera recursiva, clonando todos los objetos hijos con la única excepción de las tablas externas , stages internos y snowpipes internos que no serán clonados.
A diferencia de la clonación de tablas, cuando se realiza la clonación de un esquema o una base de datos todos los permisos son heredados, por tanto, todos los objetos de la base de datos o del esquema clonado tendrán los mismos privilegios que tenían en el original.
Sentencia
USE ROLE ACCOUNTADMIN;
USE DATABASE WEATHER;
CREATE SCHEMA HISTORICAL_CLON CLONE HISTORICAL;
Al igual que sucedía con la clonación de tablas, la operación de clonado se realiza únicamente sobre la metadata, lo que permite que se realice en un tiempo reducido y sin necesidad de tener un virtual warehouse activo.

Para comprobar que la clonación se ha realizado de la forma esperada, podemos observar los objetos de cada una de los esquemas. Comprobamos tablas e internal stages.
SHOW TABLES IN HISTORICAL;


SHOW TABLES IN HISTORICAL_CLON;


Observamos que las tablas del esquema original y del clonado son iguales, además, se han heredado tanto owner como resto de propiedades. Como sucedía en el caso de la clonación de tablas, automatic_clustering está desactivado en las tablas del esquema clonado.
A continuación, vamos a comprobar que los internal stage del esquema original no se han clonado en el nuevo esquema
SHOW STAGES IN HISTORICAL;

SHOW STAGES IN HISTORICAL_CLON;

Clonación usando time travel
Como sucedía con el clonado de tablas, Snowflake también permite realizar el clonado de bases de datos y esquemas usando la opción de time travel.
En este caso vamos a realizar la clonación de la base de datos en un tiempo anterior a la clonación del esquema “HISTORICAL” que hemos realizado anteriormente.
CREATE DATABASE WEATHER_CLONE CLONE WEATHER at (offset => -60*60);
SHOW SCHEMAS IN WEATHER;

SHOW SCHEMAS IN WEATHER_CLONE;

Podemos comprobar en la base de datos clonada que no se encuentra el esquema que hemos clonado anteriormente.
Secuencias y foreign key:
Como se comentó anteriormente en el clonado de tablas, si se clona un esquema que contiene una tabla con una columna con un valor por defecto de una secuencia o una foreign key y están en el mismo esquema o base de datos, la referencia de la secuencia apuntará a la misma referencia en el esquema o base de datos clonada.
Se ha añadido al esquema “HISTORICAL” una tabla “event_temperature” que contiene una secuencia y una foreign key a otra tabla. Se realiza la clonación:
CREATE SCHEMA HISTORICAL_CLON_2 CLONE HISTORICAL;
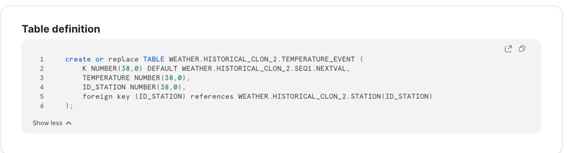
Si se observa la definición de la table, podemos comprobar cómo se ha cambiado la referencia tanto de la secuencia como de la foreign key.
Consideraciones del clonado de esquemas y bases de datos
- Para el clonado de esquemas y bases de datos hay que tener en cuenta las mismas consideraciones observadas en la parte de las tablas.
- Cuando se clona una base de datos o un esquema que contiene tareas, las tareas del clon se suspenden de forma predeterminada.
- La clonación es rápida, pero no instantánea, especialmente para objetos grandes. Por tanto, si se ejecutan comandos de DDL en los objetos de origen mientras la operación de clonación está en curso, es posible que los cambios no sean reflejados en objeto clonado.
Conclusiones
Como vimos también en los artículos anteriores, Snowflake nos ofrece muchas características avanzadas, es muy importante comprender el funcionamiento de cada una de ellas para poder sacar el máximo partido siendo este el objetivo principal de esta serie de artículos. En este caso, comprender correctamente el clonado de datos nos va a ayudar a poder utilizar esta característica de manera correcta cuando sea necesario como puede ser en la creación de entornos de prueba o en la realización de snapshot.
Finalmente, hay que destacar que Snowflake nos ofrece un potente mecanismo de clonado de objetos, permitiéndonos la clonación de una forma sencilla, apenas incurriendo en costes y sin duplicación de datos. Estas características pueden ser muy importantes cuando vayamos a seleccionar un datawarehouse para nuestro entorno analitico.
¿Quieres saber más de lo que ofrecemos y ver otros casos de éxito?
Roberto García Parra
Technical Delivery Manager
Gabriel Gallardo Ruiz
Enterprise Architect
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar