

Big Data & Cloud Architect

Cloud Data Solutions Engineer/Architect

Analytics Engineer | GCP | AWS | Python Dev | Azure | Databricks | Spark

Cloud Engineer | 3x AWS Certified | 2x HashiCorp Certified | GitHub: ajaen4

Este artículo es el segundo de una serie de dos que pretende abordar la integración de Databricks en entornos AWS analizando las alternativas ofrecidas por el producto respecto al diseño de arquitectura. En el primero se habló acerca de temas más relacionados con la arquitectura y networking, en esta segunda entrega hablaremos sobre temas relacionados con la seguridad y administración general.
Los contenidos de cada artículo son los siguientes:
Primera entrega:
Esta entrega:
El primer artículo puede visitarse en el siguiente enlace
Visita Data security and encryption en esté enlace
Databricks presenta configuraciones de seguridad de datos para proteger la información que está en tránsito o en reposo. En la documentación se ofrece una descripción general de las características de encriptación disponibles. Dichas características incluyen claves gestionadas por el cliente para encriptación, encriptación del tráfico entre nodos de clúster, encriptación de consultas y resultados, y encriptación de buckets S3 en reposo.
Hay que destacar que dentro del soporte para claves gestionadas por el cliente, que permite la protección y control de acceso a datos en el control plane de Databricks, como archivos fuente de notebooks, resultados de notebooks, secretos, consultas SQL y tokens de acceso personal. También se puede configurar claves para encriptar datos en el bucket S3 raíz y volúmenes EBS del clúster.
Otra posibilidad que ofrece Databricks es la de utilizar claves de AWS KMS para encriptar consultas de SQL y su historial almacenado en el control plane.
Por último, también facilita la encriptación del tráfico entre nodos de clúster y la administración de configuraciones de seguridad del workspace por parte de los administradores.
En este articulo hablaremos sobre dos de las opciones: customer-managed keys y el encriptado del trafico entre nodos workers del clúster
Visita Customer-managed keys en esté enlace
Los administradores de cuentas de Databricks pueden configurar claves gestionadas para la encriptación. Se destacan dos casos de uso para agregar una clave gestionada por el cliente: datos de servicios gestionados en el control plane de Databricks (como notebooks, secretos y consultas SQL) y almacenamiento del workspaces (buckets S3 raíz y volúmenes EBS).
Hay que destacar que las claves gestionadas para volúmenes EBS no se aplican a recursos de cómputo serverless, ya que estos discos son efímeros y están vinculados al ciclo de vida de la carga de trabajo serverless. En la documentación de Databricks existen comparaciones de los casos de uso de claves gestionadas por el cliente y se menciona que esta función está disponible en la subcripción Enterprise.
Respecto al concepto de configuraciones de claves de encriptación, estos son objetos a nivel de cuenta que hacen referencia a las claves en la nube del usuario. Los administradores de cuentas pueden crear estas configuraciones en la consola de la cuenta y asociarlas con uno o más workspaces. El proceso de configuración implica la creación o selección de una clave simétrica en AWS KMS y la posterior edición de la política de la clave para permitir a Databricks realizar operaciones de encriptación y desencriptación. Se pueden consultar en la documentación las instrucciones detalladas junto con ejemplos de políticas JSON necesarias para ambas configuraciones de uso (servicios gestionados y almacenamiento workspaces).
Por último, existe la posibilidad de agregar una política de acceso a un rol IAM de cuenta cruzada (cross-account) en AWS, en caso de que la clave KMS esté en una cuenta diferente.
Para esta parte, es muy importante destacar la importancia del script de inicio (init script)
Encriptación en tránsito
en Databricks, el cual, entre otras cosas, sirve para configurar la encriptación entre nodos de workers en un clúster de Spark. Este script de inicio permite obtener un secreto de encriptación compartido a partir del scope de claves almacenado en DBFS. Si se rota el secreto actualizando el archivo del almacén de claves en DBFS, se debe reiniciar todos los clústeres en ejecución para evitar problemas de autenticación entre los workers de Spark y el driver. Señalar que, dado que el secreto compartido el cual se almacena en DBFS, cualquier usuario con acceso a DBFS puede recuperar el secreto mediante un notebook.
Se pueden utilizar instancias de AWS específicas que cifran automáticamente los datos entre los nodos de trabajadores sin necesidad de configuración adicional, pero utilizar el init-script proporciona un nivel añadido de seguridad para los datos en tránsito o un control total sobre el tipo de encriptación que se quiere aplicar.
El script será el encargado de obtener el secreto del almacén de claves y su contraseña, así como configurar los parámetros necesarios de Spark para la encriptación. Lanzado como Bash, realizará estas tareas y en caso de ser necesario, realizará una espera hasta que el archivo de almacén de claves esté disponible en DBFS y la derivación del secreto de encriptación compartido a partir del hash del archivo de almacén de claves. Una vez completada la inicialización de los nodos del driver y de los workers, todo el tráfico entre estos nodos se cifrará utilizando el archivo de almacén de claves.
Este tipo de características están dentro del plan Enterprise
Databricks admite dos tipos principales de almacenamiento persistente: DBFS (Databricks File System) y S3 (Simple Storage Service de AWS).
DBFS
DBFS es un sistema de archivos distribuido integrado directamente con Databricks, almacenando datos en el almacenamiento local del clúster y de los workspaces. Proporciona una interfaz de archivo similar a HDFS estándar y facilita la colaboración al ofrecer un lugar centralizado para almacenar y acceder a datos.
S3
Por otro lado, Databricks también puede conectarse directamente a datos almacenados en Amazon S3. Los datos en S3 son independientes de los clústeres y de los workspaces y pueden ser accedidos por varios clústeres y usuarios. S3 destaca por su escalabilidad, durabilidad y la capacidad de separar almacenamiento y cómputo, lo que facilita el acceso a datos incluso desde múltiples entornos.
En cuanto a los metastores, Databricks en AWS admite varios tipos, incluyendo:
Metastore de Hive
Databricks puede integrarse con el metastore de Hive, permitiendo a los usuarios utilizar tablas y esquemas definidos en Hive.
Metastore Glue en Data Plane
Databricks también tiene la posibilidad de alojar el metastore en el propio compute plane con Glue.
Estos metastores permiten a los usuarios gestionar y consultar metadatos de tablas, facilitando la gestión de esquemas y la integración con otros servicios de datos. La elección del metastore dependerá de los requisitos específicos del flujo de trabajo y las preferencias de gestión de metadatos en el entorno de Databricks en AWS.
Unity Catalog
Sin duda alguna, una nueva funcionalidad de Databricks que permite unificar estos metastores previos y amplifica las distintas opciones y herramientas que ofrece cada uno de ellos es el Unity Catalog
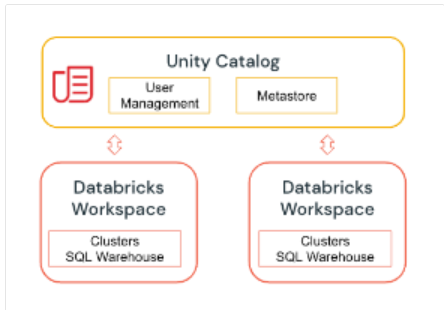
Unity Catalog proporciona capacidades centralizadas de control de acceso, auditoría, linaje y descubrimiento de datos.
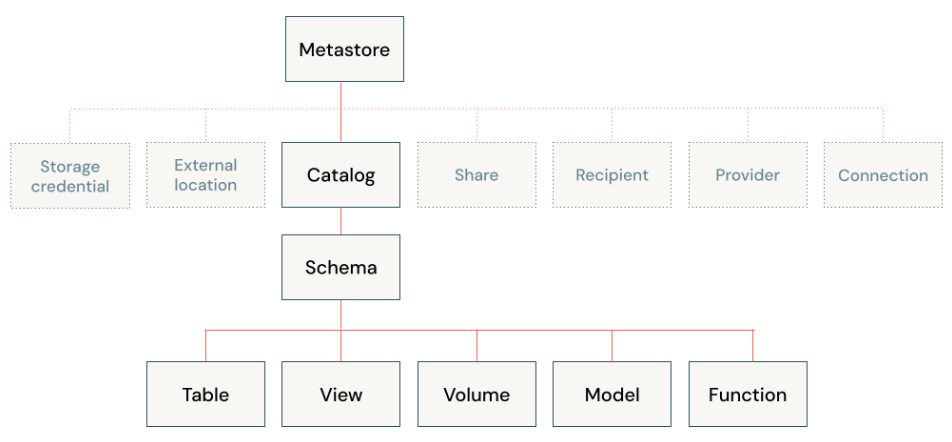
Características clave de Unity Catalog
Databricks recomienda configurar todo el acceso al almacenamiento de objetos en la nube mediante Unity Catalog para gestionar relaciones entre datos en Databricks y almacenamiento en la nube.
A continuación, se detalla la función de Databricks en AWS que permite la entrega y acceso a registros de uso facturables. Los administradores de cuenta pueden configurar la entrega diaria de registros CSV a un bucket S3 de AWS. Cada archivo CSV proporciona datos históricos sobre el uso de clústeres en Databricks, clasificándolos por criterios como ID de clúster, SKU de facturación, creador del clúster y etiquetas. La entrega incluye registros tanto para workspaces en ejecución como para aquellos cancelados, garantizando la representación adecuada del último día de dicho workspace (debe haber estado operativo al menos 24 h).
La configuración implica la creación de un bucket S3 y un rol IAM en AWS, junto con la llamada a la API de Databricks para establecer objetos de configuración de almacenamiento y credenciales. La opción de soporte de cuentas cruzadas permite la entrega a cuentas AWS diferentes mediante una política de bucket S3. Los archivos CSV se encuentran en <bucket-name>/<prefix>/billable-usage/csv/, es recomendable revisar las bestpractices de seguridad de S3.
La API de la cuenta permite configuraciones compartidas para todos los workspaces o configuraciones separadas para cada espacio o grupos. La entrega de estos CSV permite que los owners de cuentas descarguen directamente los registros. La propiedad del objeto S3 se autoconfigura como «Bucket owner preferred» para admitir la propiedad de los objetos recién creados.
Se destaca un límite en la cantidad de configuraciones de entrega de registros y se requiere ser administrador de cuenta, además de proporcionar el ID de cuenta. Especial cuidado con las dificultades de acceso si se configura la propiedad del objeto S3 como «Object writer» en lugar de «Bucket owner preferred».
| Campos paramétricos de configuración | Description |
|---|---|
| workspaceId | Workspace Id |
| timestamp | Established frequency (hourly, daily,…) |
| clusterId | Cluster Id |
| clusterName | Name assigned to the Cluster |
| clusterNodeType | Type of node assigned |
| clusterOwnerUserId | Cluster creator user id |
| clusterCustomTags | Customizable cluster information labels |
| sku | Package assigned by Databricks in relation to the cluster characteristics. |
| dbus | DBUs consumption per machine hour |
| machineHours | Cluster deployment machine hours |
| clusterOwnerUserName | Username of the cluster creator |
| tags | Customizable cluster information labels |
Big Data & Cloud Architect
Analytics Engineer | GCP | AWS | Python Dev | Azure | Databricks | Spark
Cloud Data Solutions Engineer/Architect
Cloud Engineer | 3x AWS Certified | 2x HashiCorp Certified | GitHub: ajaen4




